James E. Pustejovsky
I am a statistician and associate professor in the School of Education at the University of Wisconsin-Madison, where I teach in the Educational Psychology Department and the graduate program in Quantitative Methods. My research involves developing statistical methods for problems in education, psychology, and other areas of social science research, with a focus on methods related to research synthesis and meta-analysis.
Interests
- Meta-analysis
- Causal inference
- Robust statistical methods
- Education statistics
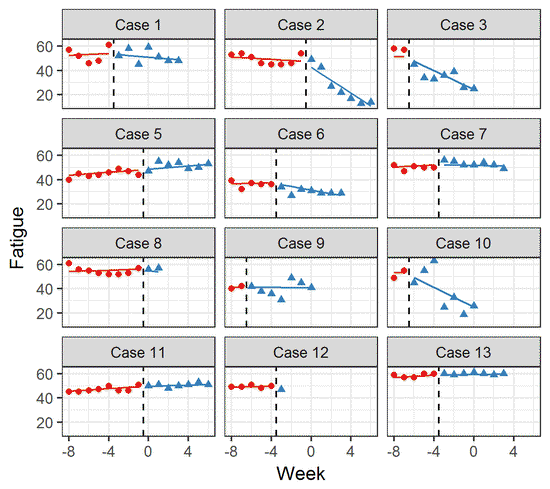
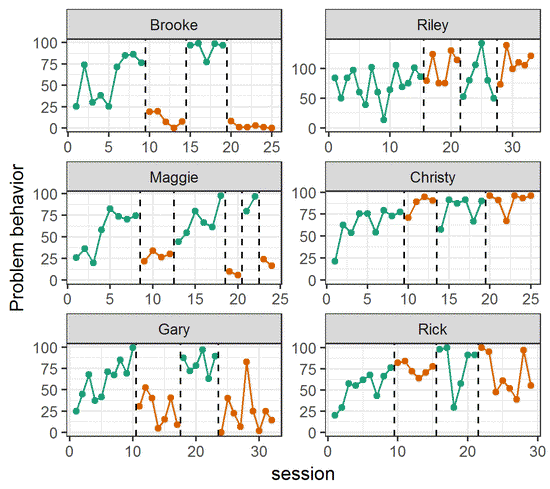
- Single case experimental designs
Education
-
PhD in Statistics, 2013
Northwestern University
-
BA in Economics, 2003
Boston College