Easily simulate thousands of single-case designs
Earlier this month, I taught at the Summer Research Training Institute on Single-Case Intervention Design and Analysis workshop, sponsored by the Institute of Education Sciences’ National Center for Special Education Research. While I was there, I shared a web-app for simulating data from a single-case design. This is a tool that I put together a couple of years ago as part of my ARPobservation R package, but haven’t ever really publicized or done anything formal with. It provides an easy way to simulate “mock” data from a single-case design where the dependent variable is measured using systematic direct observation of behavior. The simulated data can be viewed in the form of a graph or downloaded as a csv file. And it’s quite fast—simulating 1000’s of mock single-case designs takes only a few seconds. The tool also provides a visualization of the distribution of effect size estimates that you could anticipate observing in a single-case design, given a set of assumptions about how the dependent variable is measured and how it changes in response to treatment.
Demo
Here’s an example of the sort of data that the tool generates and the assumptions it asks you to make.
Say that you’re interested in evaluating the effect of a Social Stories intervention on the behavior of a child with autism spectrum disorder, and that you plan to use a treatment reversal design.
Your primary dependent variable is inappropriate play behavior, measured using frequency counts over ten minute observation sessions.
The initial baseline and treatment phases will be 7 sessions long.
At baseline, the child engages in inappropriate play at a rate of about 0.8 per minute.
You anticipate that the intervention could reduce inappropriate play by as much as 90% from baseline.
Enter all of these details and assumptions into the simulator, and it will generate a graph like this:
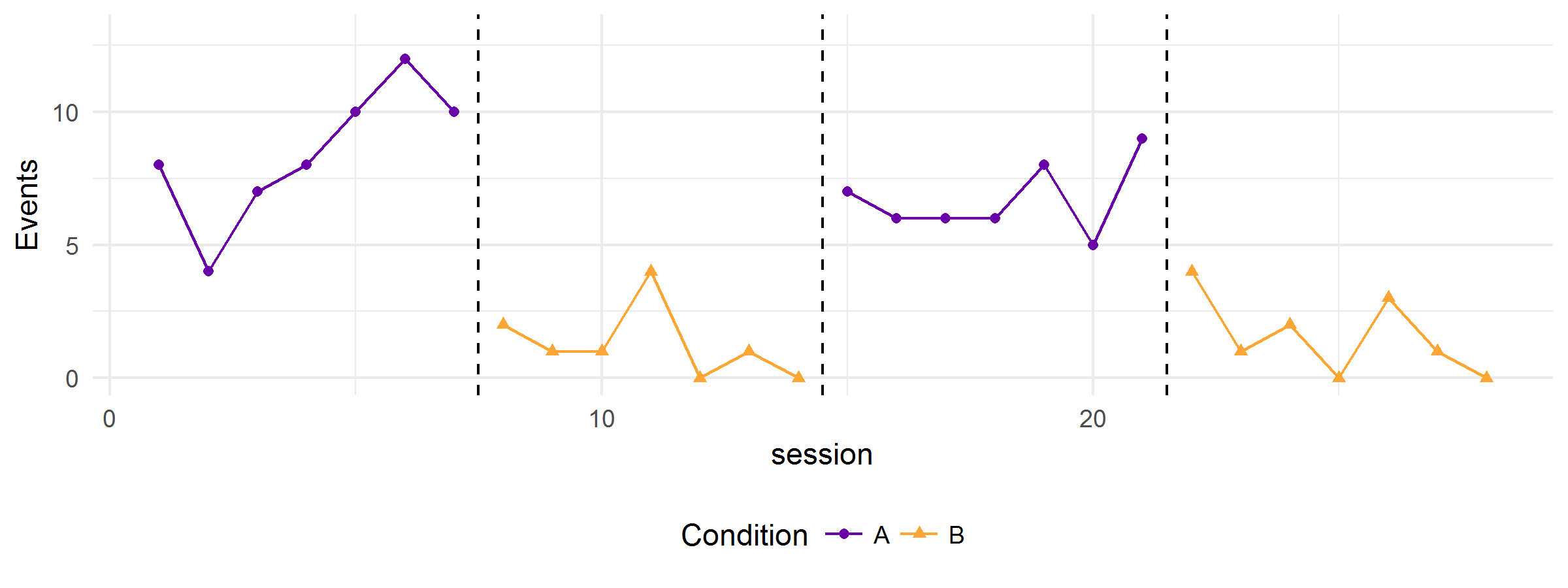
Hit the “Simulate!” button again and you might get something like this:
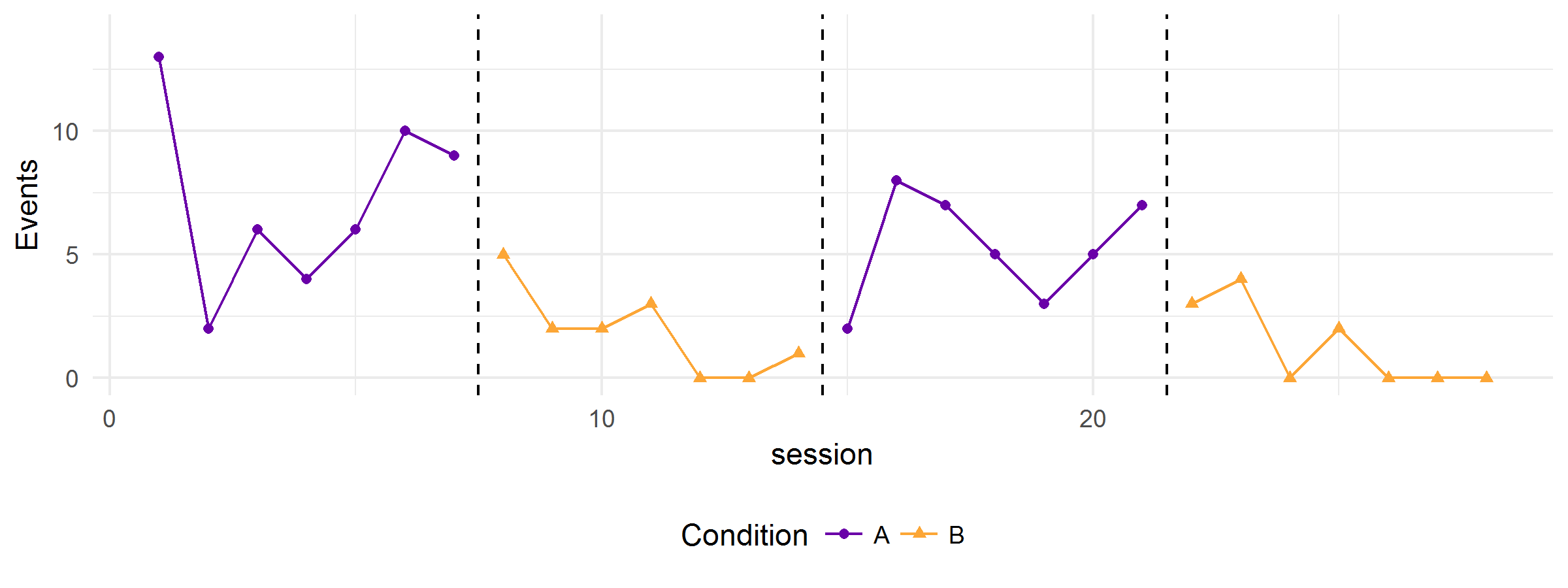
Or one of these:
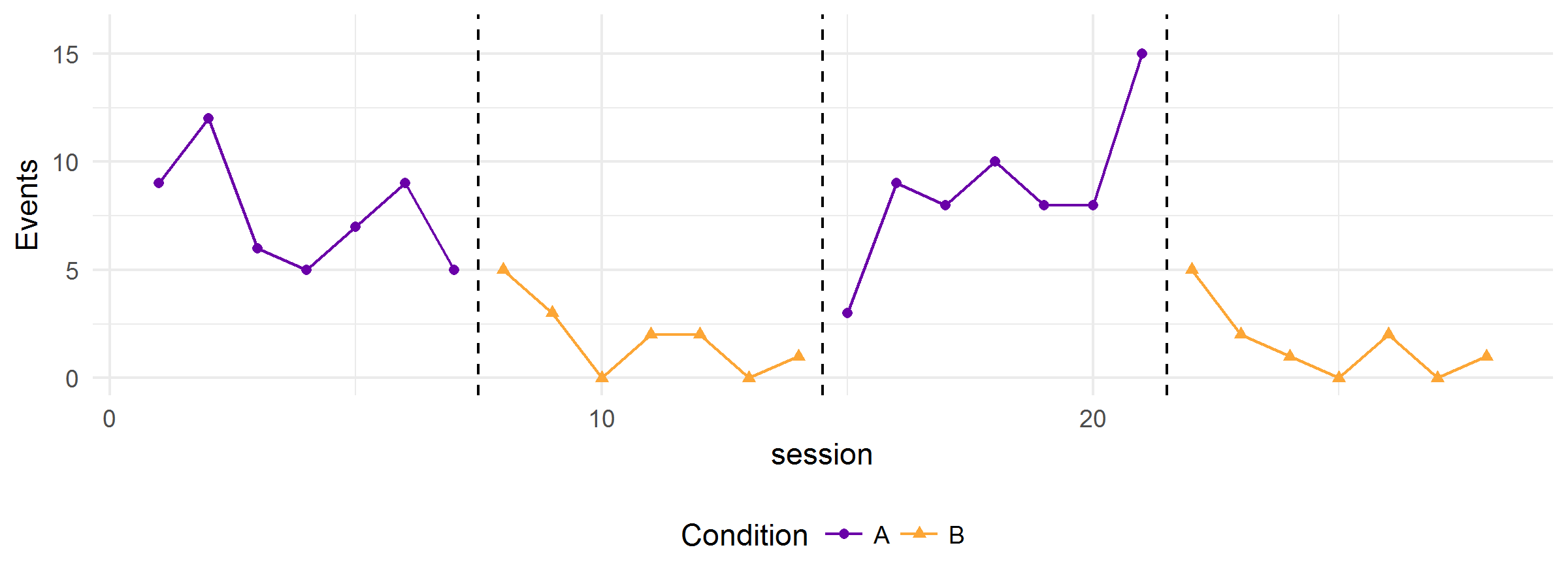
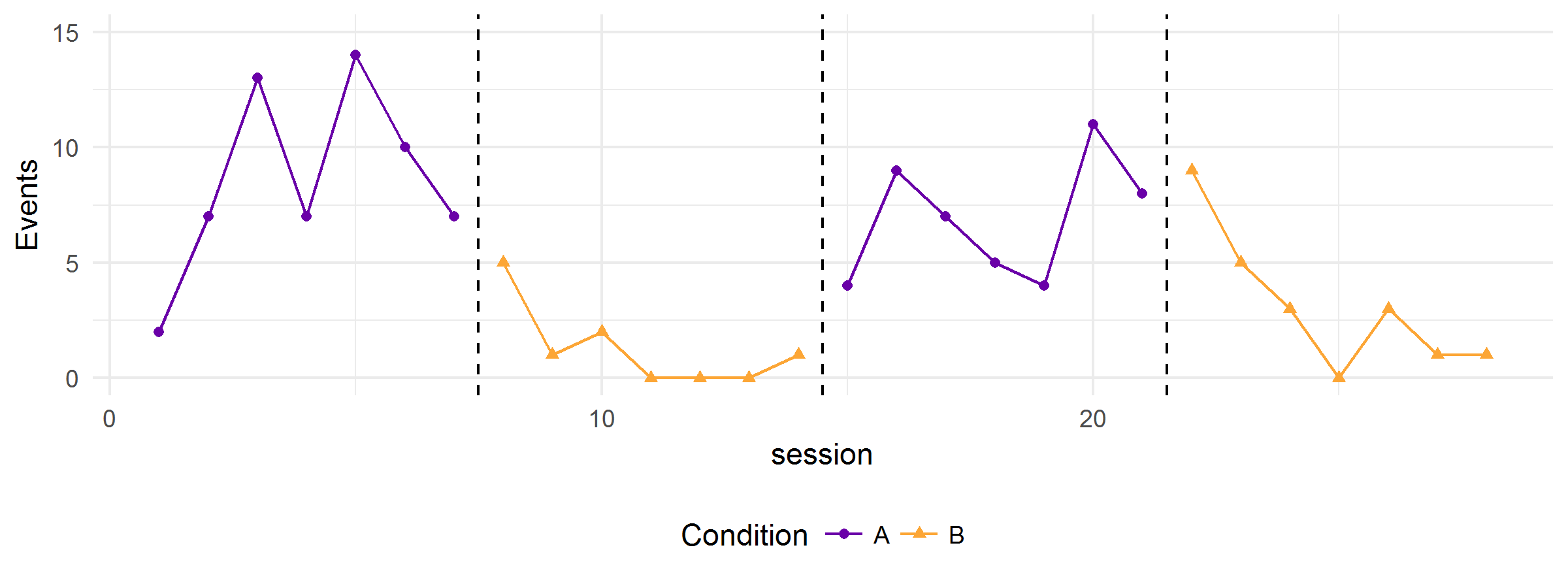
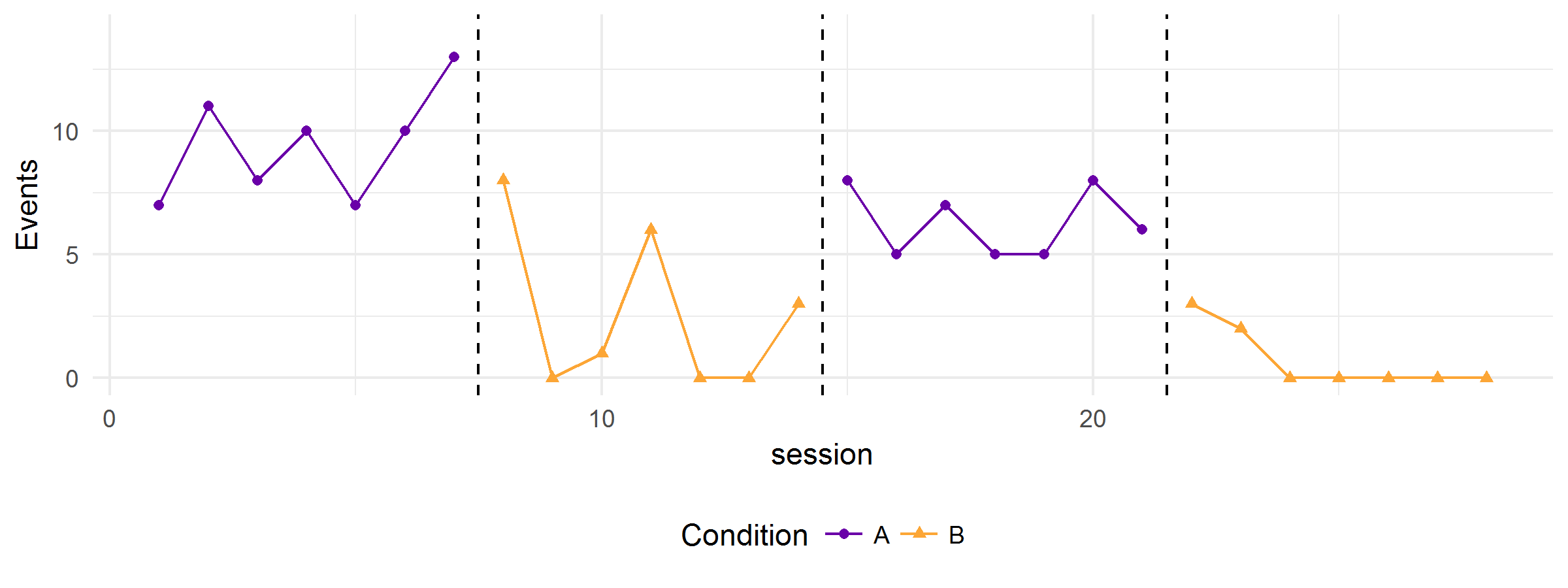
All of the above graphs were generated from the same hypothetical model—the variation in the clarity and strength of the functional relation is due to random error alone. The simulator can also produce graphs that show multiple realizations of the data-generating process. Here’s one with five replications:
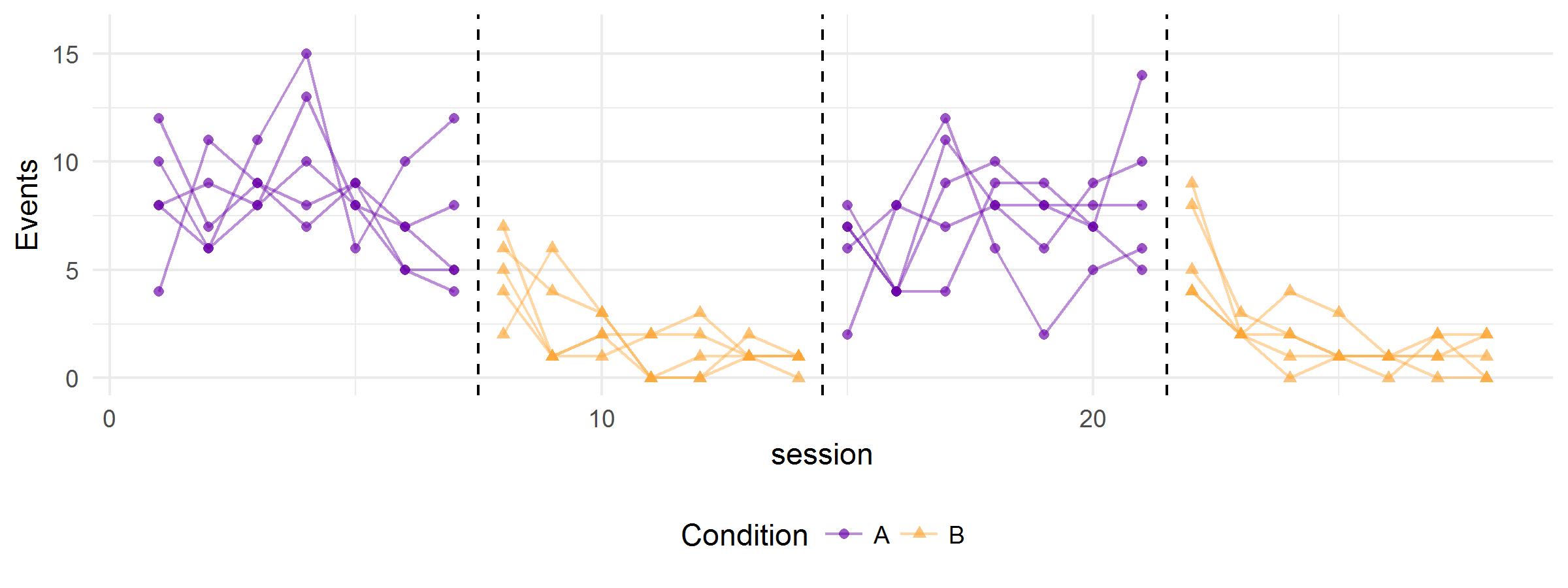
And here’s the same figure, but with trend lines added:
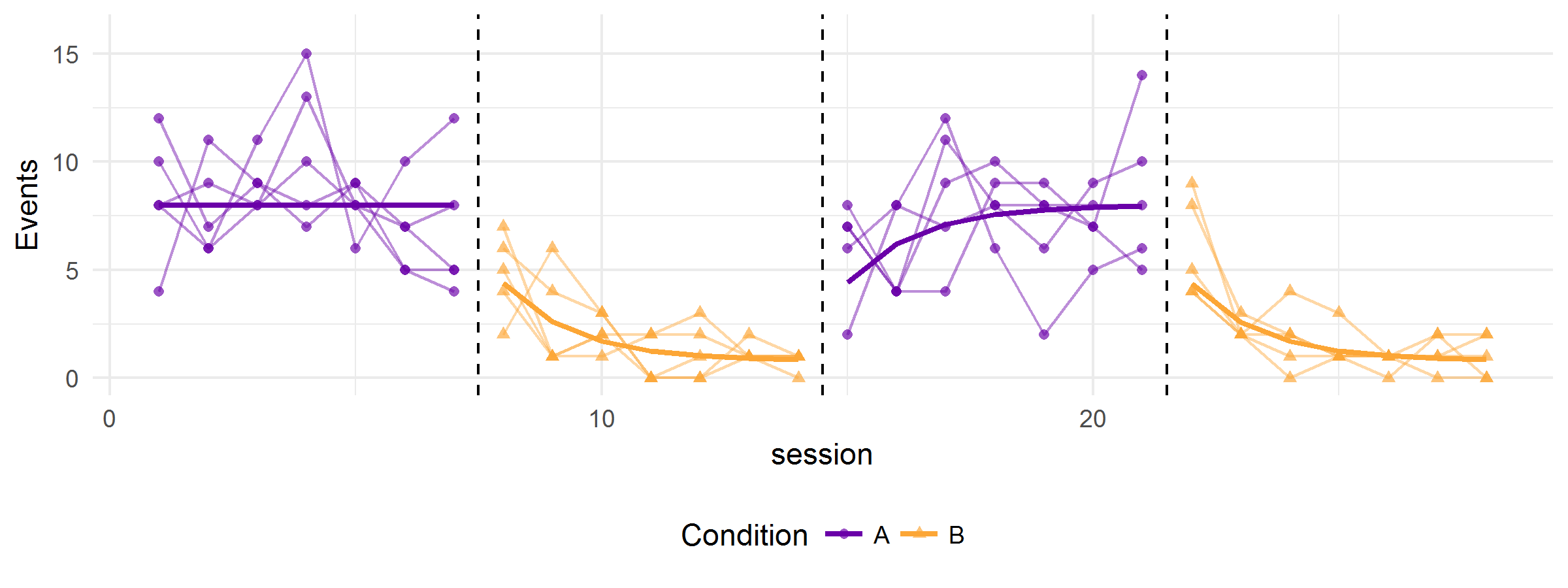
The trend lines represent the overall average level of the dependent variable during each session, across infinitely replications of the study. The variability around the trend line provides a sense of the extent of random error in the measurements of the dependent variable.
I think it’s a rather interesting exercise to try and draw inferences based on visual inspection of randomly generated graphs like this—particularly because it forces you to grapple with random measurement error in a way that using only real data (or only hand-drawn mock data) doesn’t allow. It seems like it could really help a visual analyst to calibrate their interpretations of single-case graphs with visually apparent time trends, outliers, etc.
Use cases
So far, this tool is really only a toy—something that I’ve puttered with off and on for a while, but never developed or applied for any substantive purpose. However, it occurs to me that it (or something similar to it) might have a number of purposes related to planning single-case studies, studying the process of visual inspection, or training single-case researchers.
When I originally put the tool together, the leading case I imagined was to use the tool to help researchers make principled decisions about how to measure dependent variables in single-case designs. By using the tool to simulate hypothetical single-case studies, a researcher would be able to experiment with different measurement strategies—such as using partial interval recording instead of continuous duration recording, using shorter or longer observation sessions, or using short or longer baseline phases—before collecting data on real-life behavior in the field. I’m not sure if this is something that well-trained single-case researchers would actually find helpful, but it seems like it might help a novice (like me!) to temper one’s expectations or to move towards a more reliable measurement system.
There’s been quite a bit of research examining the reliability and error rates of inferences based on visual inspection (see Chapter 4 of Kratochwill & Levin, 2014 for a review of some of this literature). Some of this work has compared the inferences drawn by novices versus experts or by un-aided visual inspection versus visual inspection supplemented with graphical guides (like trend lines). But there are many other factors that could be investigated too, such as phase lengths (this could help to better justify the WWC single-case design standards around minimum phase lengths), use of different measurement systems, or use of different design elements on single-case graphs (can we get some color on these graphs, folks?!? And stop plotting 14 different dependent variables on the same graph?!?). The simulator would be an easy way to generate the stimuli one would need to do this sort of work.
A closely related use-case is to generate stimuli for training researchers to do systematic visual inspection. Some of the SCD Institute instructors (including Tom Kratochwill, Rob Horner, Joel Levin, along with some of their other colleagues) have developed the website www.singlecase.org with a bunch of exercises meant to help researchers develop and test their visual analysis skills. It looks to me like the site uses simulated data (though I’m not entirely sure). The ARPsimulator tool could be used to do something similar, but based on a data-generating process that captures many of the features of systematic direct observation data. This might let researchers test their skills under more challenging and ambiguous, yet plausible, conditions, similar to what they will encounter when collecting real data in the field.
Future directions
A number of future directions for this project have crossed my mind:
- Currently, the outcome data are simulated as independent across observation sessions (given the true time trend). It wouldn’t be too hard to add a further option to generate auto-correlated data, although this would further increase the complexity of the model. Perhaps there would be a way to add this as an “advanced” option that would be concealed unless the user asks for it (i.e., “Are you Really Sure you want to go down this rabbit hole?”). So far, I have avoided adding these features because I’m not sure what reasonable defaults would be.
- Joel Levin, John Ferron, and some of the other SCD Institute instructors are big proponents of incorporating randomization procedures into the design of single-case studies, at least when circumstances allow. Currently, the ARPsimulator generates data based on a fixed, pre-specified design, such as an ABAB design with 6 sessions per phase or a multiple baseline design with 25 sessions total and intervention start-times of 8, 14, and 20. It wouldn’t be too hard to incorporate randomized phase-changes into the simulator. This might make a nice, contained project for a student who wants to learn more about randomization designs.
- Along similar lines, John Ferron has developed and evaluated masked visual analysis procedures, which blend randomization and traditional response-guided approaches to designing single-case studies. It would take a bit more work, but it would be pretty nifty to incorporate these designs into ARPsimulator too.
- Currently, the model behind ARPsimulator asks the user to specify a fixed baseline level of behavior, and this level of behavior is used for every simulated case—even in designs involving multiple cases. A more realistic (albeit more complicated) data-generating model would allow for between-case variation in the baseline level of behavior.
- Perhaps the most important outstanding question about the premise of this work is just how well the alternating renewal process model captures the features of real single-case data. Validating the model against empirical data from single-case studies would allow use to assess whether it is really a realistic approach to simulation, at least for certain classes of behavior. Another product of such an investigation would be to develop realistic default assumptions for the model’s parameters.
At the moment I have no plans to implement any of these unless there’s a reasonably focused need (sadly, I don’t have time to putter and putz to the same extent that I used to). If you, dear reader, would be interested in helping to pursue any of these directions, or if you have other, better ideas for how to make use of this tool, I would love to hear from you.