CRAN downloads of my packages
At AERA this past weekend, one of the recurring themes was how software availability (and its usability and default features) influences how people conduct meta-analyses. That got me thinking about the R packages that I’ve developed, how to understand the extent to which people are using them, how they’re being used, and so on. I’ve had badges on my github repos for a while now:
- clubSandwich:
- ARPobservation:
- scdhlm:
- SingleCaseES:
These statistics come from the METACRAN site, which makes available data on daily downloads of all packages on CRAN (one of the main repositories for sharing R packages). The downloads are from the RStudio mirror of CRAN, which is only one of many mirrors around the world. Although the data do not represent complete tallies of all package downloads, they are nonetheless the best available source that I’m aware of.
The thing is, the download numbers are rather hard to interpret. Beyond knowing that somebody out there is at least trying to use the tools I’ve made, it’s pretty hard to gauge whether 300 or 3000 or 3 million downloads a month is a good usage level. In this post, I’ll attempt to put just a little bit of context around these numbers. Emphasis on little bit, as I’m not all that satisfied with what I’ll show below, but at least it’s something beyond four numbers floating in the air.
Getting package download data
I used the cranlogs package to get daily download counts of all currently available CRAN packages over the period 2018-04-05 18:00:00 through 2019-04-06. I then limited the sample to packages that had been downloaded at least once between 2018-04-05 18:00:00 and 2018-10-05. This had the effect of excluding about 1000 packages that were either only recently added to CRAN or that had been discontinued but were still sitting on CRAN.
library(tidyverse)
library(lubridate)
library(cranlogs)
to_date <- "2019-04-06"
from_date <- as.character(as_date(to_date) - duration(1, "year"))
file_name <- paste0("CRAN package downloads ", to_date, ".rds")
pkg_downloads <-
available.packages() %>%
as_tibble() %>%
select(Package, Version) %>%
mutate(grp = 1 + trunc((row_number() - 1) / 100)) %>%
nest(Package, Version) %>%
mutate(downloads = map(.$data, ~ cran_downloads(packages = .$Package,
from = from_date,
to = to_date))) %>%
select(-data) %>%
unnest()downloaded_last_yr <-
pkg_downloads %>%
filter(date <= as_date(as_date(to_date) - duration(6, "months"))) %>%
group_by(package) %>%
summarise(
count = sum(count),
.groups = "drop"
) %>%
filter(count > 0) %>%
select(package)This yielded 12925 packages. For each of these packages, I then calculated the average monthly download rate over the most recent six months, along with where that rate falls as a percentile of all packages in the sample.
downloads_past_six <-
pkg_downloads %>%
filter(date > as_date(as_date(to_date) - duration(6, "months"))) %>%
semi_join(downloaded_last_yr, by = "package") %>%
group_by(package) %>%
summarise(
count = sum(count) / 6,
.groups = "drop"
) %>%
mutate(
package = fct_reorder(factor(package), count),
pct_less = cume_dist(count)
)Pusto’s packages
I have developed four packages that are currently available on CRAN:
- The
clubSandwichpackage provides cluster-robust variance estimators for a variety of different linear models (including meta-regression, hierarchical linear models, panel data models, etc.), as well as (more recently) some instrumental variables models. The package has received some attention in connection with estimating meta-analysis and meta-regression models, and it’s also relevant to applied micro-economics, field experiments, and other fields. - The
scdhlmandSingleCaseESpackages provide functions and interactive web apps for calculating various effect sizes for single-case experimental designs. TheSingleCaseESpackage is fairly new and I haven’t yet written any articles that feature it. Both it andscdhlmare relevant in fairly specialized fields where single-case experimental designs are commonly used—and where there is a need to meta-analyze results from such designs—and so I would not expect them to be widely downloaded. - The
ARPobservationpackage provides tools for simulating behavioral observation data based on an alternating renewal process model. I developed this package for my own dissertation work, and my students and I have used it in some subsequent work. I think of it mostly as a tool for my group’s work on statistical methods for single-case experimental designs, and so would not expect to be widely downloaded or used outside of this area.
As points of comparison to my contributions, it is perhaps useful to look at two popular packages for conducting meta-analysis, the metafor package and the robumeta package:
- The
metaforpackage, developed by Wolfgang Viechtbauer, has been around for 10 years and includes all sorts of incredible tools for calculating effect sizes, estimating meta-analysis and meta-regression models, investigating fitted models, and representing the results graphically. In contrast, theclubSandwichpackage is narrower in scope—it just calculates robust standard errors, confidence intervals, etc.—sometaforis not a perfect point of comparison. - The
robumetapackage, by Zachary Fisher and Elizabeth Tipton, is a closer match in terms of scope. It is used for estimating meta-regression models with robust variance estimation, using specific methods proposed by Hedges, Tipton, and Johnson (2010).
I am having a harder time thinking of good comparables for the scdhlm, SingleCaseES, and ARPobservation packages due to their specialized focus. (Ideas? Suggestions? I’m all ears!)
With that background, here are the average monthly download rates (over the past six months) for each of my four packages, along with metafor and robumeta:
library(knitr)
library(kableExtra)
Pusto_pkgs <- c("ARPobservation","scdhlm","SingleCaseES","clubSandwich")
meta_pkgs <- c("metafor","robumeta")
focal_downloads <-
downloads_past_six %>%
filter(package %in% c(Pusto_pkgs, meta_pkgs)) %>%
mutate(
count = round(count),
pct_less = round(100 * pct_less, 1)
) %>%
arrange(desc(count))
focal_downloads %>%
rename(`Average monthly downloads` = count,
`Percentile of CRAN packages` = pct_less) %>%
kable() %>%
kable_styling(bootstrap_options = c("hover", "condensed"), full_width = FALSE)| package | Average monthly downloads | Percentile of CRAN packages |
|---|---|---|
| metafor | 7348 | 94.0 |
| clubSandwich | 2992 | 90.3 |
| robumeta | 2025 | 87.9 |
| ARPobservation | 387 | 55.5 |
| SingleCaseES | 306 | 36.4 |
| scdhlm | 229 | 7.5 |
Thus, clubSandwich sits in between metafor and robumeta, at the 90th percentile among all active packages on CRAN. The other packages are much less widely downloaded, averaging between 200 and 400 downloads per month. The distribution of monthly download rates is highly skewed, as can be seen in the figure below. About 68% of packages are downloaded 500 times or fewer per month, while only 7% of packages get more than 5000 downloads per month.
library(colorspace)
library(ggrepel)
downloads_sample <-
downloads_past_six %>%
arrange(count) %>%
mutate(
focal = package %in% c(Pusto_pkgs,meta_pkgs),
tenth = (row_number(count) %% 10) == 1
) %>%
filter(focal | tenth)
focal_pkg_dat <-
downloads_sample %>%
filter(focal) %>%
mutate(Pusto = if_else(package %in% Pusto_pkgs, "Pusto","comparison"))
title_str <- paste("Average monthly downloads of R packages from", as_date(as_date(to_date) - duration(6, "months")),"through",to_date)
qualitative_hcl(n = 2, h = c(140, -30), c = 90, l = 40, register = "custom-qual")
ggplot(downloads_sample, aes(x = package, y = count)) +
geom_col() +
geom_col(data = focal_pkg_dat, aes(color = Pusto, fill = Pusto), size = 1.5) +
geom_label_repel(
data = focal_pkg_dat, aes(color = Pusto, label = package),
segment.size = 0.4,
segment.color = "grey50",
nudge_y = 0.5,
point.padding = 0.3
) +
scale_y_log10(breaks = c(20, 50, 200, 500, 2000, 5000, 20000, 50000, 200000), labels = scales::comma) +
scale_fill_discrete_qualitative(palette = "custom-qual") +
scale_color_discrete_qualitative(palette = "custom-qual") +
labs(x = "", y = "Downloads (per month)", title = title_str) +
theme(legend.position = "none", axis.line.x = element_blank(), axis.ticks.x = element_blank(), axis.text.x = element_blank())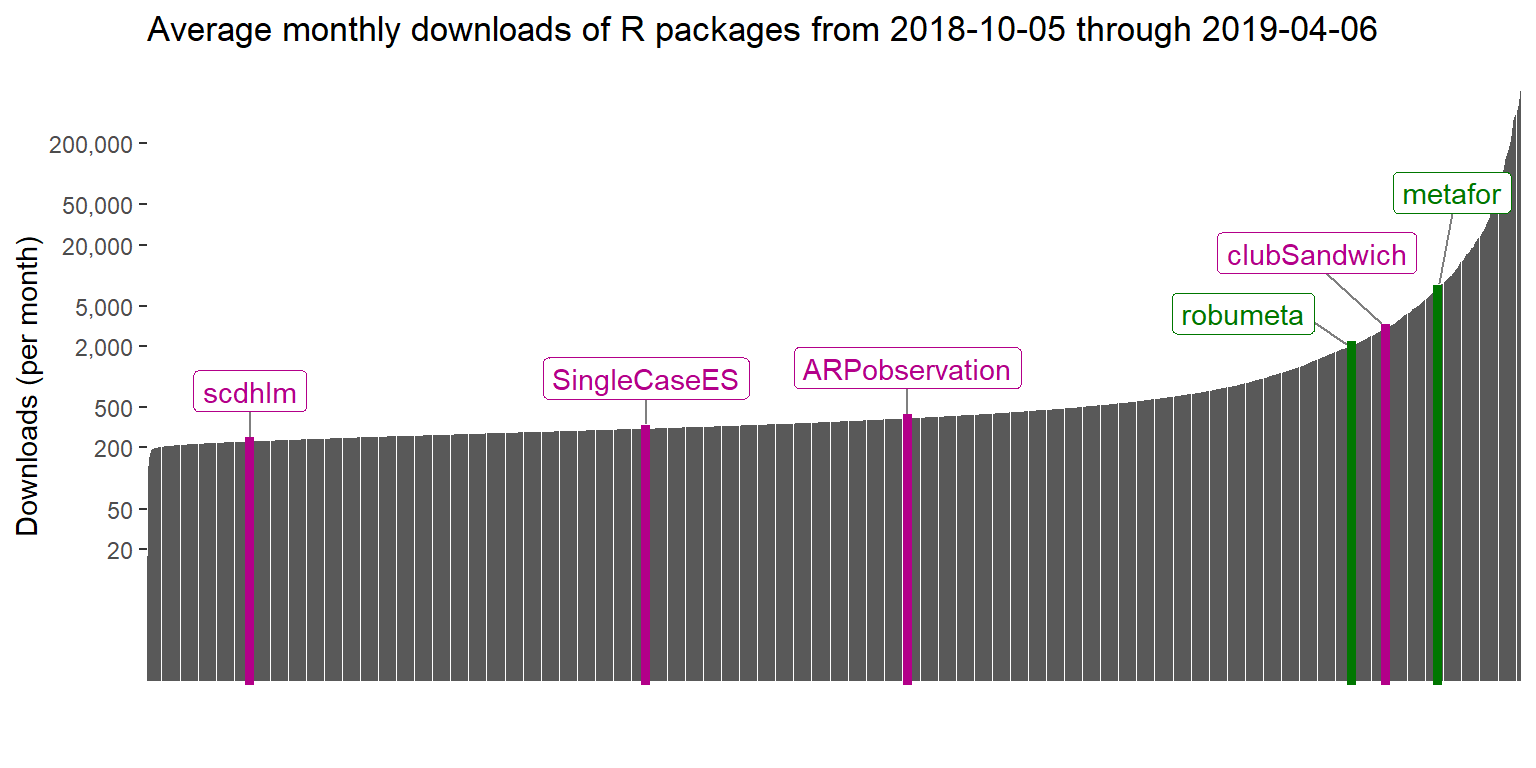
Downloads over time
Here are the weekly download rates for each of my packages over the past two years. (Note that the vertical scales of the graphs differ.)
weekly_downloads <-
pkg_downloads %>%
mutate(
yr = year(date),
wk = week(date)
) %>%
group_by(package, yr, wk) %>%
mutate(
date = max(date)
) %>%
group_by(package, date) %>%
summarise(
count = sum(count),
days = n(),
.groups = "drop"
)
weekly_downloads %>%
filter(
days == 7,
package %in% Pusto_pkgs
) %>%
ggplot(aes(date, count, color = package)) +
geom_line() +
expand_limits(y = 0) +
facet_wrap(~ package, scales = "free", ncol = 2) +
theme_minimal() +
labs(x = "", y = "Downloads (per month)") +
theme(legend.position = "none")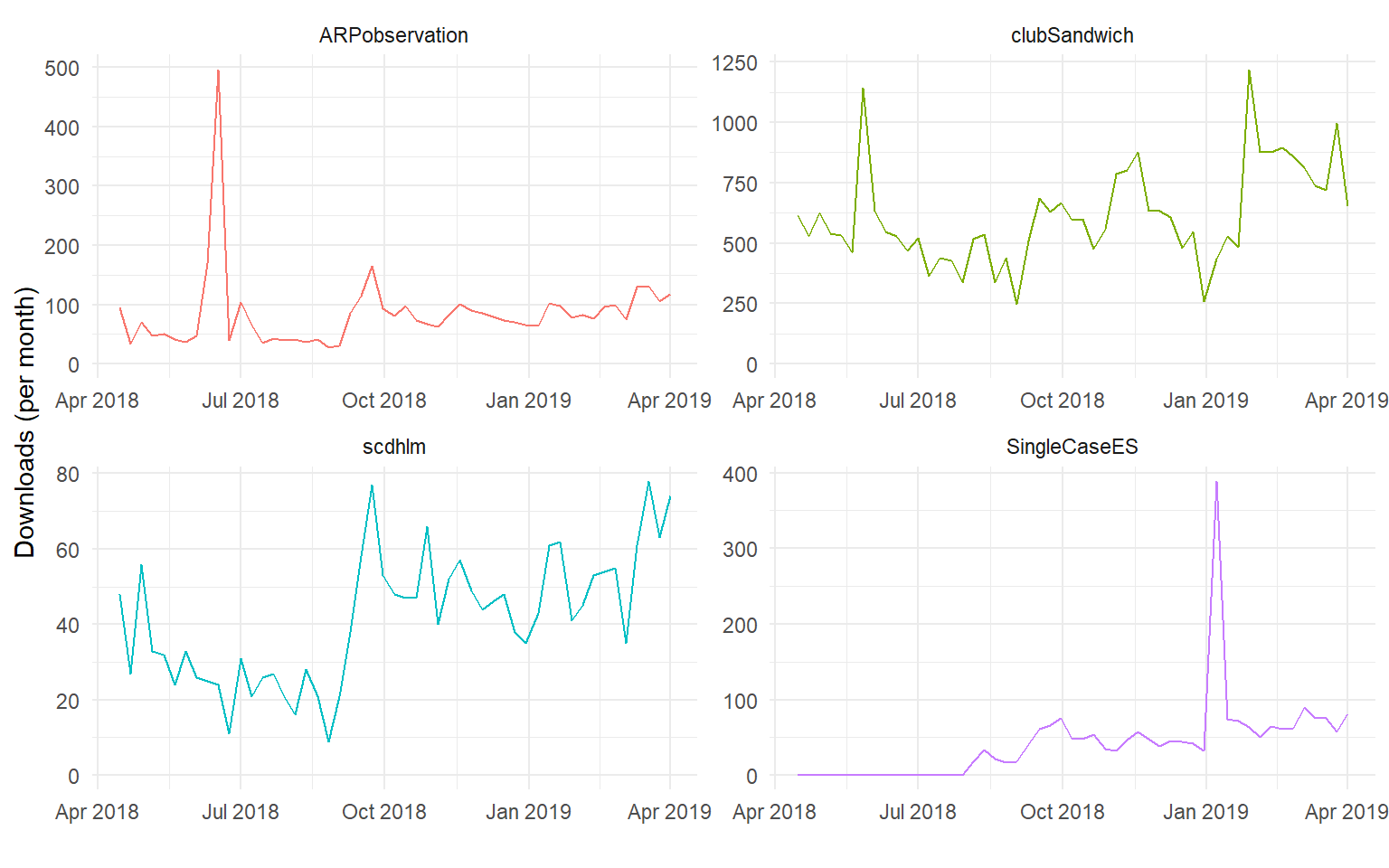
There are a couple of curious features in these plots. For one, there are big spikes in downloads of ARPobservation and SingleCaseES. The ARPobservation spike was in mid-June of 2018, when I was at the IES Single-Case Design training institute and demonstrated some of the package’s tools. The SingleCaseES spike was in early January, 2019. Perhaps someone was teaching a class in single-case research and demonstrated the package? Or something at the IES PI meeting (January 9-10, 2019)?
Another interesting pattern is in the download rate of scdhlm, which looks like it increased systematically starting in September, 2018. I wonder if this was the result of someone demonstrating or incorporating use of the package into a course. Lacking details about where the downloads are coming from, it’s hard to do anything but speculate.
Caveats and musings
Clearly, download counts are only a very rough proxy for package usage. In marketing-speak, they might be more like leads than conversion, in that people might be downloading a package only to discover that it’s not good for anything and then never use it to accomplish anything. Downloads are also not one-time events. If they use it in their work, a single person will likely download a package many times, over a span of time as new versions are released, onto multiple machines that they might use, by accident in the process of trying to install some other package, and so on. Downloads of inter-related packages are likely to be highly correlated too, as they will be with release of new major versions of R, which probably makes it a bit tricky to do event studies.
Ultimately, I don’t know that knowing where my packages stand in terms of download rankings is all that useful. The packages that I’ve developed are all aimed at fairly academic audiences, which means that citations would probably be a better measure of contribution. The problem is, many people don’t know that they should be citing software, or how to do it. As usual, there’s an R function for that. Here’s how to get the citation for clubSandwich:
citation(package="clubSandwich") %>%
print(style = "textVersion")which returns the following:
James Pustejovsky (2020). clubSandwich: Cluster-Robust (Sandwich) Variance Estimators with Small-Sample Corrections. R package version 0.5.0. https://CRAN.R-project.org/package=clubSandwich